
Table of Contents
ToggleWhat is Perplexity? complete information in Hindi
Perplexity एक मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस में इस्तेमाल होने वाला टर्म है, जिसका मुख्य उपयोग NLP (Natural Language Processing) में मॉडल की क्षमता को मापने के लिए किया जाता है कि वह किसी टेक्स्ट डाटा की भविष्यवाणी कितनी अच्छी तरह से कर सकता है |
Perplexity क्या है?
- सीधे शब्दों में, Perplexity यह बताता है कि एक भाषा मॉडल (जैसे GPT, BERT आदि) को किसी अनुक्रम (sequence) या वाक्य को सही-सही अनुमान लगाने में कितनी “confusion” हो रही है.
- कम perplexity का मतलब है कि मॉडल अच्छा परफॉर्म कर रहा है और उसका अनुमान डाटा के करीब है.
- ज्यादा perplexity मान बताता है कि मॉडल को समझने में दिक्कत हो रही है और उसके अनुमान गलत होने की संभावना अधिक है.
कब और कहाँ उपयोग होता है?
- NLP में language model की quality चेक करने के लिए.
- स्पीच रिकग्निशन, मशीन ट्रांसलेशन, टेक्स्ट जेनरेशन आदि क्षेत्रों में.
- विभिन्न भाषा मॉडल्स की तुलना के लिए कि कौन सा मॉडल बेहतर है.
आसान उदाहरण
मान लीजिए हमारे पास दो लैंग्वेज मॉडल हैं:
- मॉडल A की perplexity है 15
- मॉडल B की perplexity है 50
तो मॉडल A अच्छा प्रदर्शन करता है क्योंकि उसकी perplexity कम है, यानी वह sentences को ज्यादा अच्छे से predict करता है.
एक और संदर्भ: Perplexity.ai
- Perplexity.ai एक अलग संदर्भ है — यह एक AI-powered search engine और chatbot है जो यूजर्स के सवालों का उत्तर देता है.
- यह ChatGPT और अन्य LLMs की तरह interactive Q&A, summarization, और इंग्लिश के साथ-साथ दूसरी भाषाओं में भी जवाब देने की सुविधा देता है.
सारांश
Perplexity एक language model के “confusion” स्तर को मापने वाली इकाई है — जितनी कम perplexity, उतना बढ़िया मॉडल का प्रदर्शन. AI इंडस्ट्री में यह क्वालिटी मापने का एक लोकप्रिय और मुख्य मीट्रिक है. इसके अलावा, Perplexity.ai एक intelligent search engine और chatbot भी है.
Perplexity के बारे में कुछ महत्वपूर्ण जानकारी
Perplexity के बारे में कुछ महत्वपूर्ण जानकारी निम्नलिखित है:
परिभाषा और महत्व
- Perplexity एक मीट्रिक है जो किसी भाषा मॉडल की “अनिश्चितता” (uncertainty) या “confusion” को मापता है, यानी मॉडल किसी वाक्य में अगले शब्द की सही भविष्यवाणी कितनी अच्छी तरह कर सकता है |
- कम perplexity का अर्थ है मॉडल बेहतर परफॉर्म कर रहा है, जबकि उच्च perplexity दिखाता है कि मॉडल को अधिक कठिनाई हो रही है |
- NLP (Natural Language Processing) में large language models (LLMs) की गुणवत्ता जांचने में यह मुख्य मीट्रिक होता है |
उपयोग
- Language model का मूल्यांकन और तुलना करने के लिए
- विभिन्न डाटा सेट्स पर मॉडल की generalizability (सामान्यीकरण) को जानने के लिए
- NLP टूल्स, स्पीच रिकग्निशन, मशीन ट्रांसलेशन आदि क्षेत्रों में बहुत जरूरी मीट्रिक
सीमाएं
- केवल perplexity पर भरोसा नहीं किया जा सकता; कई बार यह मॉडल के “overall” प्रदर्शन को accurately नहीं दिखाता
- अन्य मीट्रिक्स (जैसे BLEU, ROUGE) के साथ सम्मिलित उपयोग से सही मूल्यांकन होता है
Perplexity AI
- Perplexity.ai एक ऐसा प्लेटफॉर्म है जो NLP और LLM का उपयोग कर यूजर के प्रश्नों का उत्तर रियल-टाइम में देता है, और इसका उद्देश्य जानकारी को सरल और त्वरित बनाना है
इस प्रकार, perplexity language model की भविष्यवाणी सटीकता का एक अत्यंत जरूरी मीट्रिक है, परंतु इसे अन्य मीट्रिक्स और संदर्भ के साथ समझना और इस्तेमाल करना चाहिए

मॉडल के perplexity का अर्थ अलग-अलग भाषाओं में क्या होता है?
मॉडल के perplexity का अर्थ अलग-अलग भाषाओं में भी मूल रूप से वही रहता है: यह किसी भाषा मॉडल की “अनिश्चितता” या “confusion” को मापता है कि वह अगला शब्द कितने आत्मविश्वास के साथ प्रेडिक्ट कर सकता है |
अर्थ और व्याख्या
- किसी भी भाषा (जैसे हिंदी, अंग्रेज़ी, जापानी आदि) में, perplexity कम होने का अर्थ यह है कि मॉडल उस भाषा की संरचना और शब्दों के पैटर्न को अच्छी तरह समझता है, और वह संभावना के आधार पर सही अगला शब्द चुन पा रहा है |
- यदि किसी भाषा में मॉडल के perplexity का मान अधिक है, तो इसका अर्थ है कि मॉडल उस भाषा या डाटा का pattern कम समझता है, जिससे उसकी prediction क्षमता घट जाती है |
- अलग-अलग भाषाओं में भाषा के नियम, व्याकरण, शब्द-समूह और विविधता अलग होती है, जिससे perplexity का absolute वैल्यू अलग-अलग हो सकता है, परंतु “कम perplexity = बेहतर मॉडल” का नियम हर जगह लागू होता है |
महत्वपूर्ण बातें
- अगर कोई मॉडल अंग्रेज़ी पर ट्रेन हुआ है तो उसकी अंग्रेज़ी में perplexity कम और दूसरी भाषाओं (जैसे हिंदी, चीनी आदि) में perplexity ज़्यादा हो सकती है—मॉडल की ट्रेंनिंग डाटा पर निर्भर करता है |
- इसी तरह, multilingual models (जो कई भाषाओं में ट्रेन होते हैं) वे अलग-अलग भाषाओं में अलग-अलग perplexity दिखाते हैं, भाषा की डाटा क्वालिटी और मात्र पर आधारित
- इसलिए, किसी खास भाषा में perplexity देखकर उसके लिए मॉडल की performance जाँची जाती है |
निष्कर्ष:
चाहे कोई भी भाषा हो, perplexity मॉडल की prediction सटीकता का पैमाना है, और कम perplexity उस भाषा में उच्च गुणवत्ता को दर्शाता है, मॉडल के perplexity का अर्थ अलग-अलग भाषाओं में मोटे तौर पर एक ही रहता है: वह बताता है कि मॉडल उस भाषा में कितने आत्मविश्वास के साथ सही शब्दों की भविष्यवाणी कर सकता है |
मूल अर्थ
- अंग्रेज़ी, हिंदी, फ्रेंच या किसी भी भाषा में, perplexity हमेशा मॉडल की “अनिश्चितता” या “confusion” मापने का पैमाना है—कम perplexity का मतलब बेहतर भविष्यवाणी
- अगर किसी खास भाषा में perplexity कम है, तो मॉडल उस भाषा के संरचना, वाक्य विन्यास और शब्द-संयोजन को ज्यादा अच्छे से समझता है
विभिन्न भाषाओं में फर्क
- मॉडल का perplexity अलग-अलग भाषाओं में अलग-अलग हो सकता है, इसका मुख्य कारण है भाषाई विविधता, शब्दावली का आकार, व्याकरणिक संरचना और ट्रेनिंग डाटा की मात्रा
- किसी एक भाषा में ज्यादा perplexity होने का मतलब है कि मॉडल को उस भाषा में डाटा समझने और भविष्यवाणी करने में ज्यादा दिक्कत है
- मल्टीलिंगुअल मॉडल में हर भाषा की अलग-अलग perplexity होती है, जिसकी तुलना करके उनकी performance जानी जाती है
निष्कर्ष
हर भाषा में perplexity, मॉडल की भविष्यवाणी करने की क्षमता का माप है, और इसका कम होना हमेशा बेहतर मॉडल की ओर इशारा करता है, चाहे वह कोई भी भाषा हो

भाषाई विविधता से perplexity मापन कैसे प्रभावित होता है?
भाषाई विविधता से perplexity मापन पर काफी असर पड़ता है। जब भाषा की संरचना, शब्दावली और व्याकरण बहुत विविध या जटिल होती है, तो भाषा मॉडल के लिए पैटर्न पहचानना और सही भविष्यवाणी करना मुश्किल हो जाता है, जिससे perplexity बढ़ जाती है |
मुख्य प्रभाव
- शब्दावली का आकार:- जिन भाषाओं में शब्दों की विविधता अधिक होती है, वहाँ संभावित अगले शब्दों की संख्या बहुत होती है, इससे perplexity का मान बढ़ सकता है
- व्याकरणिक संरचना:- जिन भाषाओं के नियम जटिल हैं (जैसे लिंग, काल, क्रिया-रूप आदि में बदलाव), वहाँ भी मॉडल के लिए सटीक अनुमान लगाना कठिन हो जाता है, जिससे perplexity बढ़ेगी
- डाटा क्वालिटी और मात्रा:- किसी भाषा के लिए मॉडल को जितना कम और सीमित डाटा मिलेगा, perplexity उतना ही ज्यादा हो सकता है, क्योंकि मॉडल कम पैटर्न सीख पाएगा
- बहुभाषी कॉर्पस में तुलना:- Multilingual models विभिन्न भाषाओं का अनुमान अलग-अलग accuracy के साथ लगाते हैं; समृद्ध भाषाई विविधता वाले डाटा सेट्स पर models का perplexity अधिक हो सकता है |
निष्कर्ष
भाषाई विविधता बढ़ने पर मॉडल के perplexity मापन में मुख्य रूप से वृद्धि देखने को मिलती है, क्योंकि ऐसी परिस्थितियों में मॉडल के लिए पैटर्न पहचानना व भविष्यवाणी करना अधिक चुनौतीपूर्ण हो जाता है |
उच्च-संरचनात्मक भाषा में perplexity की सीमाएँ बताइए?
उच्च-संरचनात्मक (highly structured) भाषाओं में perplexity के मापन की कुछ सीमाएँ होती हैं, जो नीचे मुख्य बिंदुओं में दी गई हैं:
प्रमुख सीमाएँ
- दीर्घकालीन संदर्भ को पकड़ने में असमर्थता:- Perplexity आमतौर पर शब्दों या टोकन के अनुमानित probabilities के औसत पर आधारित होती है, इसलिए यह भाषा के लंबे संदर्भ (long context) या संरचनात्मक पैटर्न को अच्छे से माप नहीं पाती जिससे जटिल भाषाओं में विश्वसनीयता कम हो जाती है,
- सामान्यतया केवल सांख्यिकीय माप:- Perplexity केवल मॉडल की भविष्यवाणी की अनिश्चितता को मापती है, लेकिन भाषाई अर्थ, व्याकरणिक उचितता, या प्रासंगिकता जैसे महत्वपूर्ण पहलुओं का मूल्यांकन नहीं करती
- संरचनात्मक जटिलता में असफल:- उच्च-संरचनात्मक भाषाओं में जटिल व्याकरण और नियम होते हैं, पर perplexity ऐसे नियमों के अनुसार मॉडल की क्षमता को पूरी तरह से पकड़ने में सक्षम नहीं होती
- टोकनिंग और शब्दावली पर संवेदनशीलता:- किसी भाषा की जटिल संरचना के कारण टोकनिंग प्रक्रिया प्रभावित होती है, जिससे perplexity की गणना में भिन्नता आती है और तुलना करना मुश्किल हो जाता है |
सारांश
इस प्रकार, उच्च-संरचनात्मक भाषाओं में perplexity मेट्रिक मॉडल के प्रदर्शन का एक सीमित और अधूरा आकलन करती है, खासकर जब लंबे संदर्भ, व्याकरणिक सहीपन और भाषाई समझ की बात आती है। इसलिए इसे अन्य जटिल मीट्रिक्स और मानव मूल्यांकन के साथ उपयोग करना जरूरी होता है |
किस प्रकार के टोकन perplexity को छुपा देते हैं?
Perplexity को छुपाने वाले या भ्रमित करने वाले टोकन (tokens) मुख्य रूप से वे होते हैं जो भाषा मॉडल की लंबी-संदर्भ (long-context) क्षमताओं को ठीक से नहीं मापते और जिनका वास्तविक अर्थ या जवाब देने में बहुत कम योगदान होता है। इन्हें “non-answer tokens” या “long-context-agnostic tokens” भी कहा जाता है |
विवरण
- अधिकांश टोकन ऐसे होते हैं जो भाषा मॉडल की लॉन्ग-कंटेक्स्ट समझ को प्रभावित नहीं करते, जैसे सामान्य प्रीपोजीशन्स, कॉमन शब्द, या punctuation मार्क्स, जो हर संदर्भ में अक्सर एक जैसे आते हैं। ये टोकन मॉडल की मुख्य समझ या जटिल संदर्भ कार्यक्षमता को छुपा देते हैं और perplexity मापन को कम सटीक बनाते हैं |
- जब perplexity को सभी टोकनों के समान औसत के रूप में लिया जाता है, तो ये आम टोकन “key tokens” के प्रभाव को दबा देते हैं, इसलिए मॉडल की असली लंबी संदर्भ क्षमताओं का अभिप्राय नहीं मिलता
- रिसर्च के अनुसार, “answer tokens” जो सीधे प्रश्न या संदर्भ से जुड़े होते हैं, perplexity के साथ ज्यादा संबंधित होते हैं, जबकि अन्य टोकन इसके प्रभाव को छुपाते हैं |
- इस समस्या को दूर करने के लिए नए उपाय जैसे LongPPL (Long-context Perplexity) टोकनों की पहचान कर केवल उनके आधार पर perplexity मापने का प्रयास करते हैं, जिससे वास्तविक प्रदर्शन बेहतर समझा जा सके
निष्कर्ष
इसीलिए, वे टोकन जो कि संदर्भ या उत्तर से कम जुड़े होते हैं और जो अक्सर सामान्य या निष्क्रिय होते हैं, perplexity के वास्तविक मापन को छुपा देते हैं और मॉडल की वास्तविक क्षमता को सही ढंग से प्रतिबिंबित नहीं करते
कौन से टोकन “नॉन‑आंसर” या कम‑सूचनात्मक माने जाते हैं?
“नॉन‑आंसर” या कम‑सूचनात्मक (low-information) टोकन वे होते हैं जो भाषा मॉडल के उत्तर या कॉन्टेक्स्ट में महत्वपूर्ण जानकारी नहीं देते और अक्सर सामान्य, पुनरावृत्ति वाले या केवल सिंटैक्स सम्बंधित तत्व होते हैं |
प्रमुख नॉन-आंसर टोकन
- सामान्य शब्द और प्रीपोजीशन्स:- जैसे “का”, “को”, “है”, “और”, “पर”, “से” आदि, जो अक्सर हर वाक्य में आते हैं लेकिन विशेष अर्थ या संदर्भ को प्रभावित नहीं करते
- सिंटैक्स संबंधित टोकन:- जैसे कॉमा (,), पूर्ण विराम (.), प्रश्नवाचक चिन्ह (?) या अन्य विराम चिन्ह जो केवल व्याकरणिक रूप से वाक्यों को जोड़ते हैं
- छोटे एवं सामान्य शब्द:- जैसे “यह”, “वह”, “कहा”, “था”, “था” आदि जो बहुत सामान्य होते हैं और आंख खोलने वाले टोकन नहीं होते
- दूसरे रिपीटेड टोकन:- जो पूरे टेक्स्ट में बार-बार बिना बहुत बदलाव के आते हैं, ये भी कम‑सूचनात्मक माने जाते हैं क्योंकि इनका मॉडल की सटीकता या भविष्यवाणी पर कम प्रभाव होता है |
कारण:- ये टोकन मॉडल की भविष्यवाणी की जटिलता (perplexity) को छुपा देते हैं क्योंकि ये लगभग हर संदर्भ में आसानी से अनुमानित किए जा सकते हैं, जिससे perplexity की औसत मान कम हो जाती है और मॉडल का वास्तविक प्रदर्शन छिप जाता है |
इसलिए, “नॉन‑आंसर” टोकन वे हैं जो संदर्भ या उत्तर से जुड़े हुए महत्वपूर्ण अर्थ या जानकारी नहीं देते और अधिकतर व्याकरण या सामान्य संरचना के लिए उपयोग होते हैं |
long‑context पर कौन से टोकन प्रभाव कम करते हैं?
Long-context पर प्रभाव कम करने वाले टोकन वे होते हैं जो लंबे संदर्भ (long-context) की जानकारी को कमजोर या अस्पष्ट कर देते हैं, अर्थात् ऐसे टोकन जिनका संदर्भ से सीधा या महत्वपूर्ण संबंध नहीं होता और जो मॉडल की लंबी संदर्भ क्षमताओं को छुपा देते हैं |
ऐसे टोकनों के प्रकार
- रिपीटेड सामान्य टोकन:- जैसे सामान्य प्रीपोजीशन्स, कॉमन छोटे शब्द (जैसे “का”, “है”, “और”) जो लगभग हर संदर्भ में बार-बार आते हैं, और इसलिए लंबी संदर्भ की समझ में कम योगदान करते हैं
- पंक्चुएशन और सिंटैक्स टोकन:- कॉमा, पूर्ण विराम, सवालिया चिन्ह आदि जो केवल व्याकरण को स्पष्ट करते हैं, ये भी लंबी संदर्भ की जटिलताओं को छिपा देते हैं
- कम-जानकारी वाले टोकन:- वे टोकन जो अनिवार्य रूप से बिना अतिरिक्त संदर्भ के प्रेडिक्ट किए जा सकते हैं या जिनका पूरे टेक्स्ट पर न्यूनतम प्रभाव होता है
प्रभाव
- ये टोकन मॉडल की perplexity और प्रदर्शन के औसत में छुपाव पैदा करते हैं, जिससे वास्तविक लंबी संदर्भ क्षमता का उचित आकलन करना कठिन हो जाता है
- मॉडल के लिए जरूरी “key tokens” की तुलना में इन टोकनों का मात्रा में अधिक होना, संदर्भ सूचना को कम महत्त्व देता है
इसलिए, long-context पर प्रभाव कम करने वाले टोकन वे सामान्य, पुनरावृत्त और कम-संकेत वाले टोकन होते हैं, जो संदर्भ की गहराई और जटिलता को दबा देते हैं
YouTube channel कैसे बनाएं?
youtube चैनल पर सब्सक्राइबर कैसे बढ़ाएं?
WordPress पर Blog कैसे बनाए ?
मेरे ई-कॉमर्स के लिए किस प्रकार का SSL सर्वोत्तम है?
WordPress पर Blog कैसे बनाए ?
Hostinger से Hosting कैसे खरीदे?
Domain और hosting के बीच क्या अंतर है और किसे चुनें?
Blog कैसे लिखे और एक सही Blog कैसे लिखा जाता है?
टोकन‑लेवल perplexity कैसे निकाले और विश्लेषण कैसे करें?
टोकन-लेवल perplexity निकालना और विश्लेषण करना भाषा मॉडल के प्रदर्शन को शब्द-दर-शब्द समझने का तरीका है, जिससे पता चलता है कि मॉडल किन शब्दों पर अधिक भ्रमित या असमंजस में है।
टोकन-लेवल perplexity निकालने का तरीका
- प्रत्येक टोकन की प्रेडिक्टेड probability प्राप्त करें: भाषा मॉडल से हर टोकन [ wi ] के लिए उसकी conditional probability [ P(wi | w<i}) ] प्राप्त करें, जहाँ [ w<i} ] पिछले टोकन का संदर्भ है।
- प्रत्येक टोकन के log probability का नकारात्मक लेना:
-Log P(wi | w<i)

विश्लेषण कैसे करें
- अधिक perplexity वाले टोकन:- जो टोकन कम probability के साथ प्रेडिक्ट किए गए हों (अर्थात् [ PPi ] अधिक हो), वे मॉडल के लिए कठिन या भ्रमित करने वाले टोकन माने जाते हैं। ये टोकन मॉडल की कमजोरी या कम समझ वाले क्षेत्र दिखाते हैं।
- कम perplexity वाले टोकन:- जिनका probability उच्च हो (अर्थात् [ PPi ] कम हो), वे टोकन मॉडल द्वारा अच्छी तरह समझे जाते हैं। ये सामान्य या सरल शब्द होते हैं।
- टोकन-लेवल ग्राफ:- टोकन-लेवल perplexity को ग्राफ के रूप में दर्शाकर समय के साथ मॉडल की समझ या जटिल शब्दों पर प्रदर्शन का विश्लेषण किया जा सकता है।
उपयोग
- मॉडल की कमजोरियों की पहचान के लिए।
- ट्रेनिंग या फाइन-ट्यूनिंग के दौरान विशिष्ट टोकन सुधार के लिए।
- भाषाई जटिलता वाले शब्दों या क्षेत्रों की खोज के लिए।
इस प्रकार, टोकन-लेवल perplexity निकालने से मॉडल की संदर्भ-विशिष्ट भविष्यवाणी सटीकता को विस्तार से समझा जा सकता है और सुधार के क्षेत्र चिन्हित किए जा सकते हैं |
perplexity के सभी प्लान बताएं ?
Perplexity AI की 2025 में उपलब्ध प्रमुख प्लान निम्नलिखित हैं:
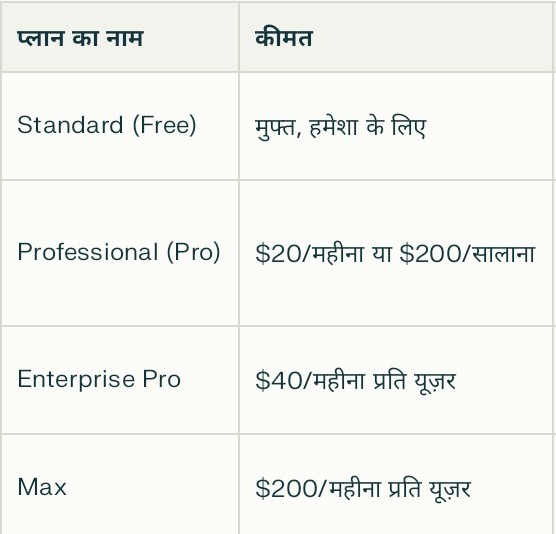


अन्य जानकारियां
- Enterprise प्लान में कस्टमाइजेशन, टीम प्रबंधन और सिक्योरिटी फीचर्स शामिल हैं।
- API उपयोग के लिए Pro और Enterprise योजना में प्रति माह $5 का API क्रेडिट मिलता है।
- Max प्लान में AI मॉडल का सबसे उन्नत संस्करण और अतिरिक्त टूल्स मिलते हैं |
इस प्रकार, Perplexity AI अलग-अलग जरूरतों के अनुसार फ्री से लेकर हाईएंड एंटरप्राइज तक विभिन्न प्लान प्रदान करता है जिनमें उपयोग सीमा, मॉडल एक्सेस, फीचर्स और सपोर्ट की विभिन्नताएं होती हैं |
Pro और Enterprise प्लान के बीच प्रमुख अंतर क्या हैं?
Pro और Enterprise प्लान के बीच प्रमुख अंतर निम्नलिखित हैं:
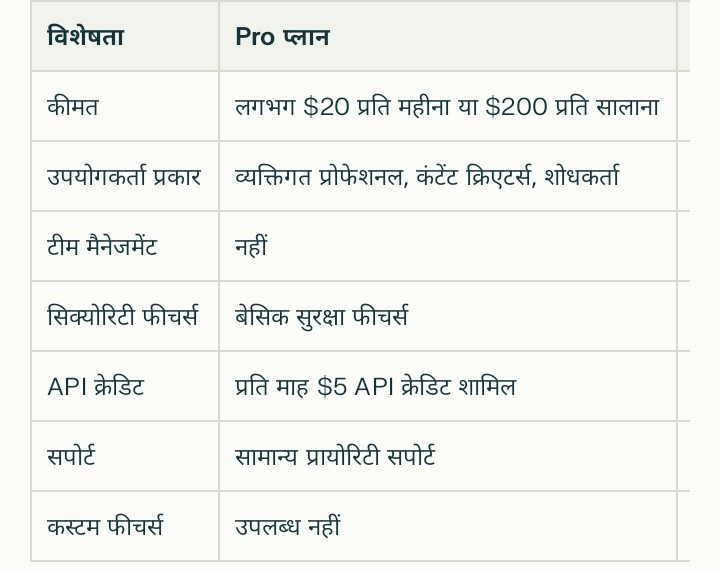

सारांश
Pro प्लान व्यक्तिगत और छोटे प्रोफेशनल उपयोग के लिए है जिसमें उन्नत AI मॉडल तक पहुँच और सीमित API क्रेडिट मिलते हैं जबकि Enterprise प्लान बड़ी टीमें और संगठन के लिए है जहाँ बेहतर सिक्योरिटी, टीम मैनेजमेंट, और कस्टम सपोर्ट जैसी अतिरिक्त सुविधाएँ मिलती हैं |
What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,
What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,What is Perplexity? complete information in Hindi,
1 thought on “What is Perplexity? complete information in Hindi”